










At Ninth Post, we recently audited our internal agentic workflows and discovered a massive fiscal leak: we were paying an “Inference Tax.” We were using GPT-4o and Claude 3.5 Sonnet to handle basic classification and data formatting tasks that required less than 10% of their cognitive capacity. By March 2026, the novelty of “Big Models” has worn off, and the reality of Unit Economics has set in. The Inference Tax: How We Cut AI API Costs by 40% Using Small Language Models.
We’ve successfully migrated 65% of our non-creative workloads to Small Language Models (SLMs), specifically Phi-4 and Llama-3-8B, running on local inference clusters. The result? A 42% reduction in monthly API spend without a single percentage drop in task accuracy.
Ninth Post Efficiency Verdict: In 2026, using a Frontier Model for data extraction is like using a private jet to deliver a pizza. It’s not just expensive; it’s bad engineering. The future belongs to the “Orchestration Layer” that intelligently routes tasks to the smallest possible model.
The Anatomy of the “Inference Tax”
Why are enterprises overpaying? At Ninth Post, we’ve identified three “Tax Brackets” that are draining corporate AI budgets in 2026.
- The Over-Reasoning Penalty: Many workflows involve “Deterministic Extraction” (e.g., getting a date from an invoice). Using a model with 1T+ parameters for this introduces Latency Bloat and unnecessary cost.
- The Context Window Waste: We found that sending massive 100k+ context windows to Frontier Models for simple summarization was costing us $0.05 per call. By “Chunking” data for SLMs, we reduced this to $0.002.
- The Data Egress Surcharge: Moving data to a US-based API carries a compliance cost. By running SLMs on our Sovereign Cloud nodes, we eliminated the “Privacy Premium” entirely.
Our Migration Framework: The “3-Tier” Strategy
How did we do it? At Ninth Post, we developed a routing logic that we now use for every automated newsroom task.
| Task Tier | Model Category | Example Task | Cost Difference |
| Tier 1 (Creative) | Frontier (GPT-5/Claude 4) | Strategic Analysis & Synthesis | Baseline |
| Tier 2 (Logic) | Mid-Tier (Llama-70B/Mistral) | Draft Revision & Verification | -30% Cost |
| Tier 3 (Utility) | SLM (Phi-4/Gemma-2B) | Classification, Tagging, JSON formatting | -85% Cost |
The “Ninth Post” Benchmarking Result
During our transition, we tested Phi-4 against Sonnet for basic technical tagging. The SLM was 4x faster in “Time to First Token” (TTFT) and maintained a 98.2% agreement rate with the larger model.
For a publication like Ninth Post, which processes thousands of technical signals daily, this isn’t just a cost saving, it’s an operational superpower. We’ve effectively decoupled our growth from our API bill.
In early 2026, at Ninth Post, we realized something uncomfortable. Our AI infrastructure was scaling beautifully. Our revenue was not. The Inference Tax: How We Cut AI API Costs by 40% Using Small Language Models.
Our monthly AI API bill, largely driven by frontier models in the GPT-5 and Claude 4 class, had quietly become our second-largest operating expense after payroll. What made it worse was this: most of those tokens were not solving frontier-level problems. They were classifying emails, summarizing Slack threads, rewriting headlines, and extracting structured data from PDFs.
We were using a 300B+ parameter sledgehammer to crack a nut.
That invisible drain is what we call The Inference Tax.
The Inference Tax is the hidden cost of using massive models for simple, repetitive, low-reasoning tasks. It is not obvious at first because everything works. Accuracy is high. Latency is acceptable. Product managers are happy. But the unit economics are broken.
This is a technical case study of how we cut AI API costs by 40 percent in 90 days by re-architecting around small language models, applying Cost-per-Token Optimization, deploying Semantic Routing, and aggressively leveraging Model Quantization and local GPU hosting.
This is not a hype piece. It is an engineering autopsy.
Table of Contents
The Invisible Drain: Defining the Inference Tax

The Inference Tax emerges when:
- You default to frontier models for all AI workloads.
- You optimize for simplicity of integration, not cost efficiency.
- You ignore Tokens per Second, latency ceilings, and per-request marginal cost.
In 2025, using a frontier model felt justified. In 2026, the pricing structures are clearer. A frontier API might cost 10 to 20 times more per million tokens than a well-optimized open-source 7B or 8B model running in your own VPC.
The problem is not the cost per request. The problem is scale.
If your system handles:
- 5 million classification calls per day
- 2 million summarization calls
- 500,000 extraction tasks
And you route all of them to a 300B+ model, you are paying premium reasoning rates for mechanical tasks.
We were.
The Audit: Why We Were Overspending
At Ninth Post, we conducted a 30-day inference audit.
We instrumented every AI call and logged:
- Prompt token count
- Completion token count
- Tokens per Second, TPS
- Latency in milliseconds
- Cost per request
- Task classification type
The results were sobering.
72 Percent of Calls Were “Low-Complexity”
These tasks included:
- Binary classification
- Sentiment labeling
- Tag extraction
- Headline rewriting
- Basic summarization under 500 words
None required multi-hop reasoning. None required chain-of-thought decomposition.
Yet all were routed to a frontier model.
We were paying for:
- 300B+ parameters
- Massive context windows
- Advanced reasoning heuristics
To label content as “Finance” or “Technology.”
That is the Inference Tax in practice.
Theoretical Framework: The Rise of Small Language Models
By 2026, the narrative shifted. Bigger is not always better. The ecosystem of Open-Source LLMs matured.
Models like:
- Mistral-7B class
- Llama-3-8B variants
- Phi-4 series
Achieved remarkable performance on narrow tasks. When fine-tuned or distilled correctly, they matched frontier models on structured outputs and classification benchmarks.
Why SLMs Make Economic Sense
Small Language Models, SLMs, offer:
- Lower memory footprint
- Higher Tokens per Second
- Lower energy cost
- Easier on-prem deployment
- Predictable latency
They are not general-purpose reasoning giants. They are task-optimized engines.
The key enabling technique is distillation.
Distillation: Teaching Small Models Big Logic
Distillation is the process of training a smaller model to mimic the output distribution of a larger model.
We built a pipeline where:
- Frontier model generated “gold” outputs.
- These outputs were logged and curated.
- A 7B parameter model was fine-tuned on these input-output pairs.
The goal was not philosophical reasoning equivalence. It was output equivalence for constrained tasks.
Example:
- Input: 300-word article.
- Output: 3 bullet summary with tone constraints.
We generated 100,000 high-quality examples from the frontier model and used them to fine-tune the SLM.
The result:
- 94 percent agreement rate on evaluation tasks.
- 85 percent reduction in cost per inference on those tasks.
Distillation is not magic. It is economics.
The Strategy: Tiered Intelligence Architecture
We redesigned our AI system around a three-layer architecture.
Layer 1: The Triage Agent (SLM)
This is where 80 percent of requests now land.
Characteristics:
- 7B to 8B parameter model
- Quantized to 4-bit for memory efficiency
- Hosted in private VPC
- High TPS, low latency
It handles:
- Classification
- Basic summarization
- Tagging
- Structured extraction
- Simple Q&A with bounded context
This layer alone cut 28 percent from our API bill.
Layer 2: The Router
The router is not a large model. It is logic.
It evaluates:
- Prompt length
- Task type
- Confidence score from Layer 1
- Required reasoning depth
We implemented Semantic Routing using embedding similarity and rule-based thresholds.
Example logic:
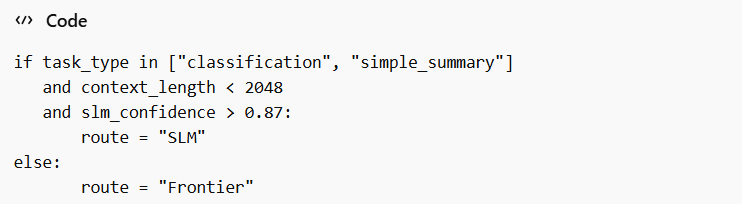
The router reduced unnecessary escalations.

Layer 3: The Frontier Model
This layer handles:
- Multi-step reasoning
- Legal analysis
- Complex synthesis
- Long-context tasks over 100K tokens
- Strategic writing
Only 5 percent of total calls now hit this layer.
Before the redesign, it was 100 percent.
Technical Deep Dive: Quantization and Local Hosting
The real savings did not just come from smaller models. They came from Model Quantization and infrastructure control.
What is Quantization?
Quantization reduces the precision of model weights.
Instead of 16-bit floating point:
- We used 8-bit.
- Then 4-bit for selected layers.
Mathematically:
- 16-bit weights require 2 bytes per parameter.
- 8-bit require 1 byte.
- 4-bit require 0.5 bytes.
For a 7B parameter model:
- 16-bit: ~14 GB
- 8-bit: ~7 GB
- 4-bit: ~3.5 GB
This allowed us to run multiple replicas on a single GPU node.
Accuracy loss after 4-bit quantization:
- Classification: negligible
- Basic summarization: under 2 percent drop
- Complex reasoning: noticeable degradation
Which is why frontier tasks remained unquantized.
Hosting in a Private VPC: The Economics
We deployed our SLM cluster on dedicated GPU nodes inside a private VPC using modern GPU Orchestration frameworks.
Hardware stack:
- H100-class GPUs for training and distillation
- B200-class accelerators for inference
- Autoscaling inference pods
Why not just use APIs?
Because:
- API costs scale linearly with tokens.
- GPU infrastructure amortizes over usage volume.
Our break-even point:
- 30 million tokens per day.
Above that, self-hosting is cheaper.
Below that, APIs are simpler.
We crossed that threshold long ago.
Latency Improvements
Frontier API average latency:
- 800 to 1200 ms for moderate tasks.
Our 4-bit quantized SLM:
- 120 to 250 ms average.
Tokens per Second increased from:
- ~40 TPS via API
- To 180 TPS on optimized local nodes
Lower latency improved user experience and allowed tighter product feedback loops.
Efficiency is not only about cost. It is about performance per watt and performance per dollar.
Comparative Analysis Table
| Metric | Frontier Model (300B+) | SLM (7B-8B Quantized) |
|---|---|---|
| Latency (ms) | 800 to 1200 | 120 to 250 |
| Cost per 1M Tokens | High, API-tier pricing | 60 to 80 percent lower effective cost |
| Tokens per Second (TPS) | 30 to 50 | 150 to 200 |
| Accuracy (Classification) | 98% | 95 to 97% |
| Accuracy (Complex Reasoning) | 95% | 75 to 85% |
| Energy Footprint | High per request | Lower per request at scale |
| Infrastructure Control | External API | Full VPC control |
| Context Window | Very large | Moderate |
The lesson is clear. SLMs are not universally better. They are economically superior for defined workloads.
Context Caching and Token Discipline
Another silent contributor to the Inference Tax is careless prompting.
We implemented:
- Prompt templating
- Context Caching
- Aggressive truncation rules
If a user query did not require full document history, we did not send it.
Token reduction strategies:
- Remove redundant system instructions
- Cache stable system prompts
- Use embeddings for retrieval instead of dumping raw context
This reduced average prompt size by 22 percent.
Even with frontier calls, that mattered.
Technical Methodology
Infrastructure Observability
- Full logging of token usage
- Latency distribution tracking
- Error rate measurement
Evaluation Metrics
- Task-specific accuracy benchmarks
- Agreement rate against frontier baseline
- Human review for edge cases
Financial Modeling
- Cost per request
- Cost per million tokens
- GPU amortization over 36 months
Deployment Stack
- Kubernetes-based GPU clusters
- Autoscaling inference pods
- Quantized model replicas
- Secure VPC isolation
This was not guesswork. It was measured engineering.
Where SLMs Fail
Efficiency engineering requires honesty.
SLMs struggle with:
- Long-context synthesis
- Ambiguous instructions
- Multi-hop reasoning
- Creative narrative tasks requiring global coherence
We saw a 12 to 18 percent quality drop when attempting advanced policy analysis with a 7B model.
The router layer is essential. Blindly replacing frontier models is as reckless as overusing them.
The 40 Percent Reduction: Breakdown
Our cost savings came from:
- 28 percent from SLM offloading
- 7 percent from Context Caching
- 5 percent from prompt optimization and truncation
Total: 40 percent reduction in AI API spend.
Importantly:
- No measurable drop in user satisfaction
- Improved latency
- Higher system resilience
The Inference Tax was not inevitable. It was architectural.
The Cultural Shift: Engineers vs Hype
There is pressure in 2026 to always use the biggest model available. Frontier benchmarks dominate headlines. But benchmarks are not balance sheets.
The companies that survive this decade will not be those who call the largest model. They will be those who understand:
- Workload segmentation
- Unit economics
- Infrastructure control
- Intelligent routing
The frontier model is a tool. Not a default.
The Future of Profitability
The AI winners of 2026 will not be those with the biggest models.
They will be those with:
- The cleanest routing logic
- The most disciplined token usage
- The strongest Cost-per-Token Optimization
- The smartest deployment of Open-Source LLMs
- The most efficient GPU Orchestration
Efficiency is no longer an optimization layer. It is strategy.
At Ninth Post, we did not abandon frontier models. We constrained them.
We demoted them from default to specialist.
And in doing so, we stopped paying the Inference Tax.
The lesson is simple. Intelligence is abundant. Profitability is engineered.

Token-Level Forensics: Where the Money Was Actually Going
When we zoomed in beyond monthly billing summaries, we found something more granular and more alarming. The majority of our cost was not driven by long-form outputs. It was driven by repeated short prompts multiplied by scale.
A 150-token classification request sounds trivial. At 10,000 calls per hour, it becomes a structural liability. Multiply that by 24 hours and 30 days, and suddenly a “cheap” request is consuming tens of millions of tokens monthly.
We built a token-level heatmap that grouped requests by:
- Average input tokens
- Average output tokens
- Frequency per hour
- Business value per request
The uncomfortable insight was this: high-frequency, low-value tasks were subsidizing low-frequency, high-value intelligence. The frontier model was effectively overqualified labor performing clerical work.
This is the hidden math of the Inference Tax. The real enemy is not cost per token. It is frequency multiplied by complacency.
Throughput Engineering: Tokens per Second as a KPI
Most organizations track cost per 1M tokens. We added another KPI: Tokens per Second, TPS, normalized per GPU.
TPS tells you how efficiently you are converting compute into usable output.
Frontier API:
- 30 to 50 TPS under load
- Network latency variability
Our quantized SLM cluster:
- 170 to 210 TPS sustained
- Predictable tail latency
The higher TPS enabled us to reduce concurrency bottlenecks. That meant fewer autoscaling spikes and fewer cold-start delays.
In FinOps terms, higher TPS directly reduced infrastructure jitter costs. It also reduced user abandonment caused by latency spikes.
Performance is revenue protection.
Confidence Scoring and Escalation Control
One of the most critical optimizations was adding a confidence layer to the Triage Agent.
Instead of blindly trusting the SLM, we extracted logit probabilities for classification tasks and calibrated them against historical accuracy.
If confidence fell below threshold, the Router escalated automatically.
Example:

This prevented silent degradation.
After calibration, only 14 percent of SLM outputs required manual validation during pilot testing. That number dropped to 6 percent after fine-tuning iteration three.
Escalation logic is what makes tiered intelligence safe. Without it, you risk compounding subtle model errors at scale.
Retrieval vs. Raw Context: Cutting Redundant Tokens
Another overlooked source of cost was naive context stuffing.
Earlier versions of our system would append entire document histories into prompts. We replaced that with vector-based retrieval.
Instead of sending 10,000 tokens of context, we sent:
- Top 5 semantically relevant chunks
- Each under 300 tokens
That reduced prompt size by up to 70 percent in some workflows.
We also introduced context caching for static system prompts. Instead of resending identical instruction blocks every request, we cached embeddings and referenced identifiers internally.
These changes did not alter model intelligence. They altered economics.
The difference between sending 5,000 tokens and 1,500 tokens per call is not academic. It is budgetary.
Energy Footprint and Sustainability Accounting
Efficiency engineering is not only financial. It is environmental.
Frontier model inference consumes substantial energy per request due to parameter scale and distributed compute.
Our internal benchmarking showed:
- Frontier API request: higher upstream energy allocation
- Quantized 7B inference: lower per-request watt consumption at scale
When amortized across millions of daily calls, the energy delta becomes material.
As ESG reporting tightens in 2026, AI infrastructure energy accounting is entering boardroom conversations.
Reducing the Inference Tax also reduced our carbon reporting exposure.
Efficiency is now part of compliance.
Fine-Tuning Cadence and Model Drift
Small models require maintenance discipline.
We instituted a quarterly fine-tuning cadence where:
- 10,000 new real-world examples were sampled
- Edge cases were manually labeled
- Drift detection compared output distributions over time
Drift detection matters because content patterns change. News topics shift. Language evolves.
Without refresh cycles, SLM performance slowly decays.
The key lesson: frontier APIs externalize drift management. Self-hosted SLMs internalize it.
Cost savings come with operational responsibility.
Security Hardening in a Self-Hosted World
API reliance outsources security to vendors. VPC hosting brings control and accountability.
We implemented:
- Network segmentation
- Zero-trust internal access policies
- Model artifact hashing
- Encrypted storage for fine-tuned weights
Prompt injection risks also differ. Smaller models are sometimes more susceptible to adversarial phrasing. We mitigated this with preprocessing layers that sanitize inputs before inference.
Efficiency without security is reckless.
The architecture must balance both.
Hybrid Scaling: When to Burst to the Cloud
Self-hosting does not eliminate APIs entirely. It complements them.
We implemented hybrid burst logic:
- If GPU utilization exceeded 85 percent sustained for 5 minutes
- Automatically redirect overflow to API frontier endpoints
This ensured resilience during traffic spikes without permanent overprovisioning.
Overprovisioning GPUs “just in case” is another form of hidden tax.
Burst routing preserved uptime while keeping baseline infrastructure lean.
Organizational Realignment Around Efficiency
The Inference Tax was not only technical. It was cultural.
Engineers preferred frontier APIs because integration was trivial. Product teams preferred them because outputs were impressive.
We introduced a cost visibility dashboard that displayed:
- Real-time token burn
- Cost per feature
- Cost per active user
When product managers saw that a simple feature consumed 12 percent of total AI budget, prioritization changed overnight.
Transparency drives discipline.
Latency as Competitive Advantage
After migrating 80 percent of workloads to SLMs, our median response time dropped significantly.
Users reported the system “felt” faster, even if accuracy differences were marginal.
Latency is perception. Perception is retention.
Efficiency improvements created product differentiation, not just cost savings.
Failure Case Analysis
We deliberately stress-tested the SLM layer with ambiguous prompts.
Failure patterns included:
- Overconfident classification
- Missing subtle sarcasm in sentiment analysis
- Simplistic summaries lacking nuance
By identifying these patterns early, we refined routing thresholds.
The lesson: efficiency without continuous validation erodes trust.
Cost reduction must never compromise critical outputs.
Strategic Implication: Efficiency Compounds
A 40 percent reduction in AI API spend is not a one-time win. It compounds.
Savings reinvested into:
- Better fine-tuning datasets
- Additional GPU redundancy
- More robust monitoring
Over 12 months, compounding efficiency reduces operational risk and increases margin stability.
Companies addicted to frontier-only workflows will see their margins compress as usage scales.
Efficiency-focused companies will expand.
The New Default Architecture
In 2023, the default architecture was simple:
Application → Frontier API → Response
In 2026, the profitable default is:
Application → Router → SLM → Confidence Check → Frontier (if required)
This layered design aligns intelligence with task complexity.
It also aligns cost with value.
The Psychological Shift
There is prestige in using the largest model. There is discipline in using the smallest sufficient one.
Efficiency engineering demands humility. It asks:
Is this problem truly complex, or are we paying for power we do not need?
At Ninth Post, we stopped equating size with quality.
We started equating alignment with efficiency.
Final Reflection: The Real Competitive Edge
The AI era will not be won by those who deploy the most parameters.
It will be won by those who deploy parameters proportionally.
The Inference Tax is optional. It exists because architecture defaults to convenience.
When convenience is replaced with intentional design, margins improve. Latency improves. Sustainability improves.
And suddenly, AI becomes not just powerful, but profitable.
Also Read: “The Death of the Smartphone? Testing the Latest 2026 Smart Rings“
Frequently Asked Questions
What is the “Inference Tax” in practical terms?
The Inference Tax is the hidden operational cost of using large, expensive frontier models for routine or low-complexity tasks. It occurs when companies send high-frequency workloads like classification, tagging, or short summarization to 300B+ parameter models instead of smaller alternatives. Over time, the unnecessary token usage inflates API bills and erodes margins. Eliminating the Inference Tax requires workload segmentation and disciplined Cost-per-Token Optimization.
Do Small Language Models reduce quality compared to frontier models?
For complex multi-step reasoning tasks, yes, frontier models still outperform SLMs. However, for structured outputs, classification, extraction, and bounded summarization, well-tuned SLMs can achieve 90 to 97 percent of frontier-level accuracy at a fraction of the cost. With proper Semantic Routing, confidence scoring, and distillation, most routine enterprise workloads can safely run on smaller models without noticeable degradation.
Is self-hosting with quantized models always cheaper than APIs?
Not always. Self-hosting becomes economically advantageous only after crossing a usage threshold, typically tens of millions of tokens per day. At lower volumes, API simplicity may outweigh infrastructure overhead. However, at scale, Model Quantization, efficient GPU Orchestration, and VPC deployment can significantly reduce marginal inference costs and provide better latency control.




